在GPU行业竞争日益激烈的背景下,摩尔线程于12月20日至21日举办了首届MUSA开发者大会,正式发布新一代GPU架构“花港”及相关产品,试图在开发者生态构建和芯片性能上对标国际巨头英伟达。
此次发布会上,摩尔线程创始人张建中详细介绍了多款新产品。其中,AI训推一体芯片“华山”在浮点算力、访存带宽等关键指标上宣称已超越英伟达Hopper系列;游戏领域专业图形GPU“庐山”和智能SoC“长江”则分别针对特定场景优化;公司还推出了KUAE万卡智算集群,旨在提升大规模计算效率。根据现场披露的信息,2026年量产的第五代“花港”架构将实现算力密度提升50%、能效提升10倍,并支持十万卡级智算集群部署。
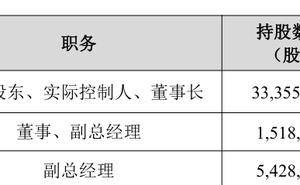
摩尔线程的团队背景与其战略方向密切相关。公司核心成员中不乏英伟达中国前员工,张建中本人更是在英伟达任职14年,曾任全球副总裁兼大中华区总经理。这种渊源使得摩尔线程在经营模式和产品规划上长期对标英伟达,尤其在生态构建、基础算力设施布局及物理AI领域表现出高度相似性。不过,与“国产GPU四小龙”其他成员及壁仞科技等企业相比,摩尔线程更强调“全功能GPU”概念,试图通过集成AI计算、图形渲染和音视频解码等功能,在性价比和便捷性上形成差异化优势。
尽管如此,国产GPU与英伟达顶尖产品仍存在性能差距。以“华山”芯片为例,其访存容量已超越Hopper系列,访存带宽与英伟达当前主流产品持平,但在浮点算力和高速互联带宽方面仍有提升空间。更值得注意的是,英伟达计划于明年量产的下一代超级芯片Rubin,可能进一步拉大技术代差。对此,张建中在发布会上援引测试数据称,基于新架构的软硬件协同优化已使摩尔线程在DeepSeek-V3和R1等主流大模型训练任务中表现优于Hopper芯片,试图打消开发者对国产芯片性能的顾虑。
当前正值AI算力需求爆发与国产化替代的双重机遇期。受美国出口管制影响,英伟达特供中国的H20芯片尚未完全恢复供应,而其Blackwell系列芯片在国内市场的渗透率也面临挑战。摩尔线程的新产品若能快速落地,或将在信创和智算中心领域进一步挤压外资品牌空间。不过,互联网数据中心及大模型训练场景仍高度依赖英伟达H系列芯片,国产替代进程仍需突破技术瓶颈和生态壁垒。
生态构建被视为摩尔线程赶超英伟达的关键战役。中国工程院院士郑纬民在大会上指出,在“主权AI”时代,算力自主、算法自强和生态自立缺一不可,而开发者生态的黏性直接决定了技术落地的广度。为此,摩尔线程宣布Musa5.0系统全面升级,宣称兼容国内外全功能GPU生态,并呼吁开发者基于国产技术栈开发应用。这一举措直指英伟达CUDA生态的垄断地位——后者长期占据行业主导权,国产芯片厂商在生态适配上面临显著挑战。
张建中对此表现出乐观态度。他认为,只要国产生态替代栈能提供足够优质的开发体验,就能吸引开发者长期投入,最终形成“用自主生态开发自主应用”的良性循环。这一战略若能成功,或将助力摩尔线程从技术追赶者转型为生态引领者,为中国GPU产业开辟新的发展路径。