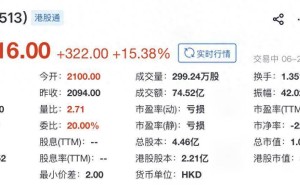
在人工智能技术飞速发展的当下,AI计算对存储系统的要求日益严苛,传统存储方案正遭遇前所未有的挑战。近日,存储行业知名企业闪迪(SanDisk)公布了一项创新专利,其核心内容是将NAND闪存与计算单元整合至单一芯片封装中,旨在突破当前高带宽内存(HBM)在供应、容量及延迟方面的限制。
当前,AI加速器和图形处理器(GPU)普遍依赖HBM提供高带宽内存支持,以满足其高速数据处理需求。然而,HBM在实际应用中面临多重困境:产能紧张导致供应不足,成本居高不下,且单堆栈容量有限,通常在32GB至64GB之间。HBM通常与主芯片并置,数据传输过程中仍存在一定延迟,这在一定程度上限制了AI计算的性能提升。
相比之下,NAND闪存具有显著优势。其容量更高,成本更低,能够满足大规模数据存储的需求。但在传统架构中,NAND闪存与计算芯片距离较远,数据传输速度远低于动态随机存取存储器(DRAM)和HBM,这成为制约其应用的关键因素。
为解决这一问题,闪迪此前提出了高带宽闪存架构(HBF)方案。该方案借鉴了HBM的层级设计理念,通过垂直堆叠多个NAND层,并利用硅通孔(TSV)技术实现互连,形成一个单一的闪存堆栈。根据规划,HBF的容量可扩展至4TB,远超当前HBM的水平,为大规模数据存储提供了新的可能。
在最新公布的专利中,闪迪进一步提出了3D堆叠方案。该专利编号为US 12,430,274 B2,其核心创新在于将基于CBA技术的NAND存储单元集成在主计算芯片下方。主计算芯片可以是GPU或AI处理器,同时,在同一中介层上继续配置HBM堆栈。这种设计使得两类存储在系统中各司其职:HBM负责处理需要即时响应的数据,确保计算的高效性;NAND则承担读写操作和大规模数据集的存储任务,提供高容量和低成本的存储解决方案。
从设计层面来看,闪迪的这一方案试图融合HBM的高带宽优势与NAND的大容量、低成本特性,并通过更宽的连接方式提升数据传输效率,同时降低系统的功耗和成本压力。然而,这项技术目前仍处于专利阶段,其实际应用仍面临诸多挑战。功耗控制、制造成本、封装复杂度以及同时集成NAND与DRAM后的量产可行性等问题,都需要进一步的研究和验证。尽管如此,业内普遍认为,闪迪的这一方案为存储与计算的深度融合提供了新的思路,展现了未来存储技术发展的潜在方向。