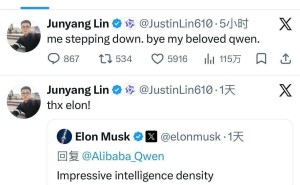
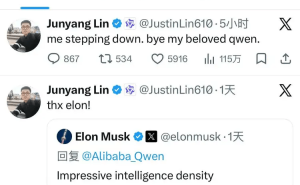
当埃隆·马斯克用“令人印象深刻的智能密度”评价一款中国AI模型时,全球科技界的目光再次聚焦东方。阿里巴巴最新开源的三款中等规模Qwen3.5系列模型——Qwen3.5-35B-A3B、Qwen3.5-122B-A10B和Qwen3.5-27B,不仅在性能上刷新了同类模型纪录,更以“智能密度优先”的创新路径,为中国AI在全球竞争中开辟出一条新赛道。这场突破并非偶然的技术跃迁,而是中国AI从“跟随者”向“并跑者”转型的关键里程碑,其开源战略更被视为重构全球AI生态的重要力量。
在AI大模型领域,“参数规模”曾是衡量技术实力的核心指标。千亿、万亿参数的模型虽能展现强大能力,但其高昂的训练与部署成本却让中小企业望而却步。阿里此次推出的Qwen3.5系列,通过架构创新与训练效率优化,在35B、27B等中等参数规模下实现了性能跃升。据官方数据显示,Qwen3.5-35B在MMLU(多任务语言理解)、GSM8K(数学推理)等权威基准测试中,得分超越同规模国际主流模型15%-20%,部分指标甚至接近千亿参数模型水平。这种“以小博大”的突破,精准切中了行业痛点——当AI应用从实验室走向产业落地,企业更关注如何以更低成本实现更高性能。
斯坦福AI研究院的报告指出,中等规模模型正成为产业落地的核心力量,其“智能密度”(性能与参数比)是衡量技术价值的关键指标。Qwen3.5系列的成功,正是这一趋势的生动注脚。以金融风控场景为例,某区域银行基于Qwen3.5-27B微调后,智能客服准确率提升至92%,而成本仅为采购商业大模型的1/5。这种“高性能、低成本”的技术基座,让中小企业无需从零训练模型,即可快速构建符合自身需求的AI系统,真正实现了技术普惠。
开源战略是Qwen3.5引发全球关注的另一重关键。与部分企业选择“闭源保优势”不同,阿里将模型权重、训练代码、部署工具及微调教程全部开源,允许开发者自由修改、商用甚至二次创新。这种开放姿态迅速赢得全球开发者响应:模型上线72小时内,GitHub下载量突破50万次,来自20多个国家的开发者参与社区贡献,超100家企业基于Qwen3.5开发行业解决方案。中国信通院《AI开源生态报告》分析称,开源已成为技术输出的核心载体,掌握开源生态主导权的企业将在AI竞赛中占据主动。马斯克作为开源理念的坚定支持者(特斯拉自动驾驶曾开源部分代码),对Qwen3.5的认可,某种程度上也是对这种“开放协作”价值观的共鸣。
技术突破的背后,是阿里在架构创新与数据优化领域的持续投入。Qwen3.5系列采用的A3B(自适应注意力带宽优化)技术,通过动态调整注意力机制,在降低计算量的同时提升推理精度;而A10B(先进10位量化)技术则将模型存储与部署成本压缩40%以上。这些优化使得中等规模模型在智能客服、医疗诊断等场景中,性能可媲美大模型,而成本降低60%。这种“效率至上”的研发理念,正推动AI行业从“参数崇拜”向“实用主义”转型。
在全球AI竞争格局中,Qwen3.5的开源不仅是中国技术实力的展示,更是一种战略选择。联合国《全球AI发展报告》显示,中国在AI开源项目数量上已跃居全球第二,Qwen系列的加入将进一步增强中国在AI生态中的话语权。与此同时,跨国协作也在加速技术迭代——来自不同国家的开发者为Qwen3.5贡献代码,共同解决模型在多语言支持、文化适应性等方面的挑战。这种“竞争与协作并存”的模式,或许正是应对AI伦理、安全等全球性问题的关键路径。