谷歌近日正式推出轻量级人工智能模型Gemini 3.1 Flash-Lite,宣称这是Gemini 3系列中速度最快、最具成本效益的版本。该模型通过Google AI Studio的Gemini API向开发者开放预览,企业用户也可在Vertex AI平台同步体验。此举标志着谷歌在降低AI应用门槛方面迈出重要一步,其定价策略引发行业关注。
在定价体系上,谷歌为该模型制定了极具竞争力的方案:每百万输入Tokens仅收费0.25美元,输出Tokens价格为1.50美元。这种定价策略显著低于同类产品,尤其适合需要处理大规模数据的场景。例如,内容审核、实时翻译等基础任务的成本将大幅降低,为中小企业采用先进AI技术创造了条件。
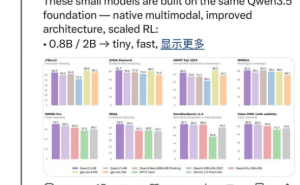
性能测试数据显示,新模型在响应速度方面实现突破性提升。根据Artificial Analysis平台的评估,与前代2.5 Flash相比,首字响应时间(TTFT)缩短至原来的40%,整体输出速度提升45%。这种低延迟特性使其特别适合需要即时交互的应用场景,如智能客服、实时数据分析等。在Arena.ai排行榜上,该模型以1432分的Elo得分证明其综合实力,在多模态理解和逻辑推理测试中均领先同级别竞品。
具体能力方面,Gemini 3.1 Flash-Lite在专业测试中表现亮眼。在GPQA Diamond测试中取得86.9%的得分率,MMMU Pro测试达到76.8%的准确率,部分指标甚至超越体积更大的2.5 Flash模型。这些数据表明,轻量化设计并未牺牲模型的核心能力,反而在特定任务中展现出更优的效率。
该模型的创新功能"思考层级"机制备受关注。开发者可根据任务复杂度动态调整模型推理深度:处理简单任务时降低层级以提升效率,面对复杂逻辑或创意生成时则提高层级激发深度思考能力。这种灵活性使单一模型能够适应从基础自动化到高级决策支持的不同场景需求。
早期采用企业已验证其实际价值。Latitude、Cartwheel等公司将其部署于用户界面生成、数据可视化等复杂业务场景,反馈显示模型在保持高效处理的同时,能准确理解复杂指令并输出高质量结果。测试团队特别指出,其推理精度可与大型模型媲美,但资源消耗和响应速度明显优于同类产品。