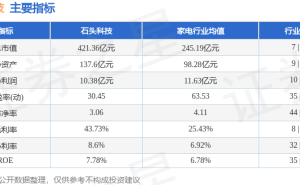
英伟达在GPU硬件与CUDA软件生态领域长期占据主导地位,其GPU算力与CUDA编程框架的组合,几乎成为AI开发领域的“标配”。然而,近期英伟达推出的一项新技术,却引发了行业对GPU编程格局变化的广泛讨论——这项被称为CUDA Tile的新语言,被指借鉴了中国团队的创新思路。
事件起因于2024年初,中国团队开发了一款名为TileLang的GPU编程语言,其设计理念与CUDA Tile高度相似。更引人注目的是,AI模型开发公司DeepSeek在发布V3.2版本时,同步推出了基于CUDA和TileLang的双版本模型。此前,DeepSeek的模型深度依赖英伟达CUDA生态,甚至部分代码直接使用英伟达专有的PTX汇编语言优化算力。而TileLang的出现,使得其模型能够轻松部署在华为昇腾等国产AI芯片上,打破了硬件绑定的局限。
这一系列动作引发了行业猜测:英伟达是否因感受到中国技术的威胁,才紧急推出CUDA Tile?尽管英伟达官方将此次更新描述为“自2006年CUDA发布以来最大的进步”,但时间上的巧合仍让人浮想联翩。
CUDA的局限性在AI时代逐渐显现。传统GPU编程依赖SIMT(单指令多线程)机制,通过统一指令控制大量线程并行执行。这种模式在图形渲染等任务中效率极高,例如处理游戏画面时,GPU可同时对数百万像素执行相同操作。但在AI推理中,计算步骤往往依赖前序结果,线程间需频繁同步,导致“快的等慢的”现象,严重浪费算力。CUDA模型不重视数据复用,中间结果需反复写入全局内存,进一步降低效率。
为应对这些问题,英伟达早在2014年推出cuDNN库,将卷积、矩阵乘法等常用AI算子封装为“预制菜”,供开发者直接调用。然而,cuDNN的封闭性限制了其灵活性——一旦模型涉及新算子,开发者仍需手动编写CUDA代码,重新处理线程调度、内存管理等底层细节。这种“手搓代码”的模式不仅开发效率低下,还容易因优化不足导致性能损失。
TileLang的创新在于,它彻底改变了开发者与GPU的交互方式。开发者只需定义计算逻辑和数据流向,线程分配、数据复用、同步时机等复杂任务均由编译器自动完成。例如,在开发MLA算子时,TileLang可将代码量从CUDA/C++的500余行压缩至80行,同时性能提升30%。这种“高层次抽象”的设计,使得即使是没有GPU编程经验的开发者,也能快速实现高效算子开发。
面对TileLang的挑战,英伟达选择主动出击。2024年12月,英伟达正式推出CUDA Tile,其核心功能与TileLang高度重合:通过自动化线程管理和数据优化,降低AI算子开发门槛。作为英伟达官方工具,CUDA Tile能够直接调用GPU底层资源,在性能优化和工具链支持上具备天然优势。对于依赖英伟达生态的开发者而言,CUDA Tile无疑是更稳妥的选择。
然而,TileLang的价值在于其开放性。传统GPU开发中,代码与硬件深度绑定,更换平台需重写大量底层逻辑。而TileLang通过抽象化硬件细节,使同一套代码可在不同厂商的GPU、TPU甚至国产AI芯片上运行。这种“一次编写,多处部署”的特性,正逐渐改变开发者对硬件生态的依赖逻辑——未来,选择GPU的标准可能从“CUDA生态是否成熟”转变为“代码能否跨平台兼容”。
类似的故事在其他领域早已上演。例如,游戏开发中,尽管DirectX 12与Windows深度绑定且性能极致,但跨平台的Vulkan仍凭借开放性分走了部分市场份额。开发者用行动证明:性能并非唯一标准,避免被单一厂商技术路线“卡脖子”,同样是重要的考量因素。