谷歌近日宣布推出全新开源大语言模型系列Gemma 4,将专有模型研发成果向全球开发者开放。这一系列包含四个不同参数规模的模型版本,既涵盖适用于移动设备的轻量化方案,也提供面向高性能计算场景的旗舰模型,标志着谷歌在开源人工智能领域迈出关键一步。
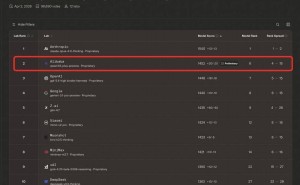
针对不同硬件环境,Gemma 4系列提供差异化解决方案:20亿和40亿参数的"Effective"模型专为智能手机等边缘设备优化,260亿参数的"专家混合"模型与310亿参数的"密集"模型则面向数据中心级应用。参数规模直接影响模型能力,参数越多通常意味着更强的语言理解能力,但也需要更强大的算力支持。谷歌特别强调,310亿参数版本在第三方评测机构Arena AI的文本生成榜单中位列第三,260亿参数版本排名第六,性能超越参数规模大20倍的竞品模型。
该系列模型具备多模态处理能力,所有版本均支持视频和图像分析,可高效完成光学字符识别等任务。轻量级版本进一步扩展至音频处理领域,能够直接理解语音输入。更值得关注的是,所有模型均具备离线代码生成能力,开发者可在无网络环境下完成编程工作。为提升全球适用性,谷歌在训练阶段纳入140余种语言数据,确保模型在多语言场景下的稳定性。
在开源协议方面,谷歌采用Apache 2.0许可证替代原有的Gemma许可证,赋予开发者更大自由度。新协议允许用户自由修改模型架构、调整参数配置,并支持在本地服务器或云端环境部署。谷歌人工智能团队负责人表示:"这种开放模式既保障数据主权,又为技术创新提供基础设施支持,开发者可以完全掌控模型从训练到部署的全生命周期。"
目前,Gemma 4系列模型权重已通过Hugging Face、Kaggle和Ollama三大平台开放下载。开发者可根据硬件条件选择适配版本,轻量级模型可在消费级显卡上运行,旗舰版本则需要专业级AI加速卡支持。这种分层开放策略既满足学术研究需求,也为商业应用提供灵活选择,预计将推动大语言模型在更多垂直领域的落地应用。