在AI界掀起巨浪的DeepSeek R1,自其诞生以来的128天里,已对整个大模型市场造成了深远影响。这款模型以惊人的力量,推动了推理模型价格的急剧下滑,使得OpenAI在六月更新的o3价格相较于o1版本,直接降至两成。
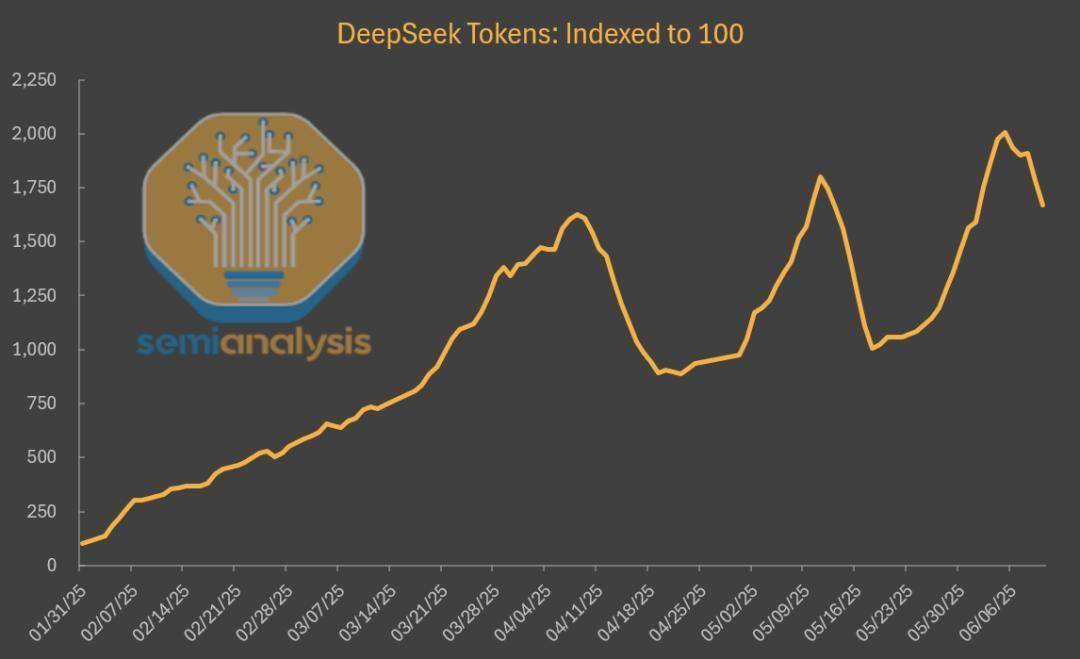
值得注意的是,DeepSeek模型的托管使用量在第三方平台上呈现出爆炸式增长,与初发布时相比,几乎激增了20倍,这一变化极大地促进了众多云计算企业的发展。然而,令人意外的是,DeepSeek自家的网站和API市场份额却并未随之水涨船高,反而出现了下滑趋势,与上半年AI产品的持续增长态势形成了鲜明对比。

据SemiAnalysis发布的一份深度报告分析,DeepSeek不仅改变了AI模型市场的竞争格局,也揭示了当前AI市场份额的最新动态。尽管DeepSeek V3与R1模型经过迭代升级,性能较1月发布时有了显著提升,且价格更为亲民,但其官方平台的使用情况却并未因此受益。
数据显示,截至5月,全网DeepSeek模型生成的token中,仅有16%来自DeepSeek官方平台。同时,其网页版聊天机器人的流量也遭遇了大幅下滑,而与此同时,其他主要大模型的网页版流量却在持续攀升。这种“墙内开花墙外香”的现象背后,实则隐藏着DeepSeek为降低成本所做的诸多妥协。
SemiAnalysis指出,用户在DeepSeek官方平台上使用模型时,往往需要等待数秒才能看到首个字符的出现,这一延迟现象在业内被称为“首token延迟”。相比之下,尽管其他平台的价格普遍更高,但其响应速度却快得多,部分平台甚至能实现几乎零延迟的体验。例如,在Parasail或Friendli等平台,用户仅需支付3-4美元,即可获得几乎没有延迟的100万token额度。而若选择更大更稳定的服务商,如微软Azure平台,虽然其价格是DeepSeek官方的2.5倍,但延迟却减少了整整25秒。
DeepSeek官方甚至不是同等延迟条件下价格最低的DeepSeek模型服务商。在价格与性能的权衡上,DeepSeek选择了在有限的推理计算资源下,仅提供64k的上下文窗口服务,这在主流模型提供商中属于最小之一。对于需要读取整个代码库的编程场景而言,64K的上下文窗口显然不够用,用户因此更倾向于选择第三方平台。而在同等价格下,Lambda和Nebius等平台能提供2.5倍以上的上下文窗口。
DeepSeek为了降低成本,还将多个用户的请求打包处理,虽然每个token的成本因此降低,但每个用户的等待时间却相应增加。这一系列降本策略均显示出DeepSeek目前对用户体验的重视程度不高,其更多地将算力资源投入到内部研发中,以实现AGI为目标。同时,通过开源策略,DeepSeek鼓励其他云服务托管其模型,以此扩大影响力和培养生态。
在DeepSeek的影响下,其他大模型供应商也开始调整策略。Claude为了缓解算力紧张的问题,降低了输出速度,但仍努力在用户体验与营收之间寻找平衡。自Claude 4 Sonnet发布以来,其输出速度已下降了40%,但仍比DeepSeek快不少。Claude模型被设计成生成更简洁的回复,相同问题下,DeepSeek和Gemini可能需要多花3倍的token。
种种迹象表明,大模型供应商正在从多个维度对模型进行改进,不仅追求模型智能上限的提升,更注重每个token所能提供的智能价值。